Apache Kudu 读写异常问题修复 & 总结
现象
2023-05-15 10:30
StreamSet (简称sdc) 服务开始告警,与 Kudu 写入相关的部分 pipeline 开始出现异常。
DolphinScheduler 部分任务出现异常告警。
应用服务部分接口也出现了超时。
由此,一个美好的周末,就此变得逐渐糟糕。
排查
初次尝试 - SDC,Impala
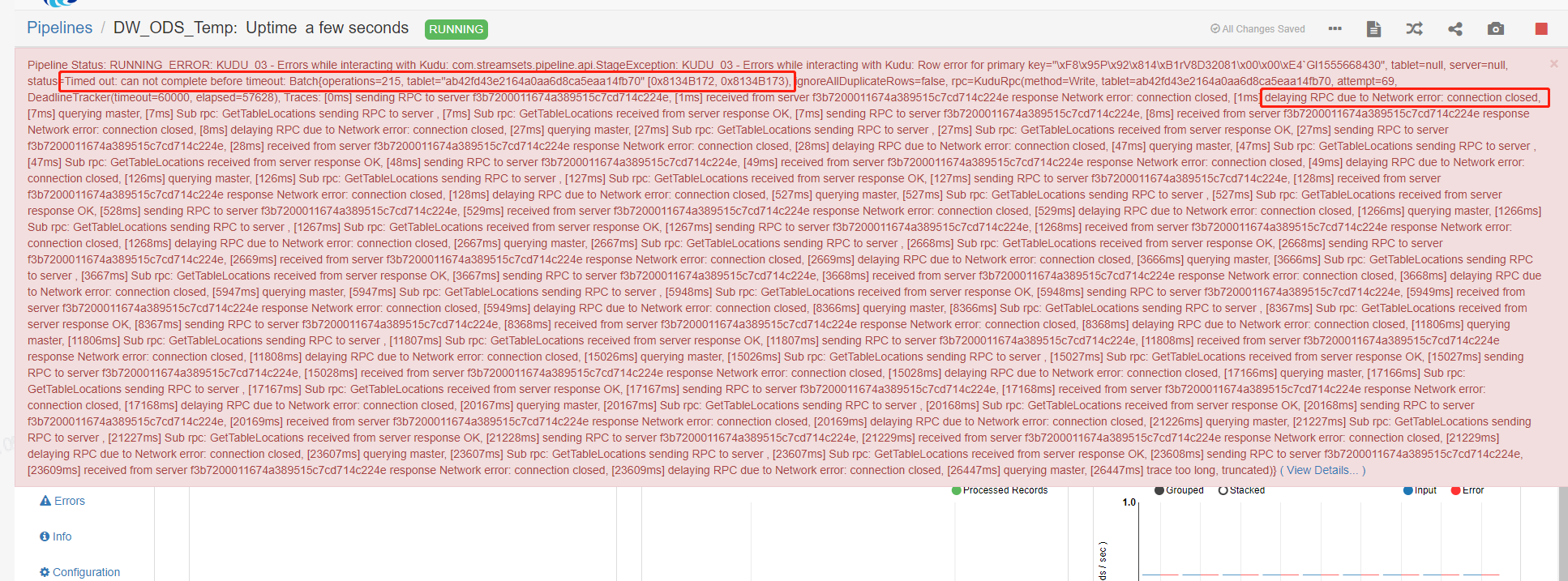
最开始只发现 SDC pipeline 异常, 报文提示为 RPC 通信失败, 怀疑是 SDC 服务异常, 于是尝试重启 SDC。但重试后异常依旧。
后面发现 Impala 读写 Kudu 表时同样存在响应超时,犯罪目标逐渐清晰,没错,该出来挨打的就是本篇主角 - Kudu。
目标清晰 - Kudu
定位到问题源头后,由于对 Kudu 不太熟悉,进行了一些尝试性操作,重点关注如下:
Kudu 的集群分布
| 节点 | master | tablet |
|---|---|---|
| pro-data-001 | tablet-server-01 | |
| pro-data-002 | tablet-server-02 | |
| pro-data-003 | master01 | tablet-server-03 |
| pro-data-004 | master02 | tablet-server-04 |
| pro-data-005 | master03 | tablet-server-05 |
第一个排查点
在几次重启后,发现 tablet-server-02 节点会一直出现异常导致节点离线。日志如下:
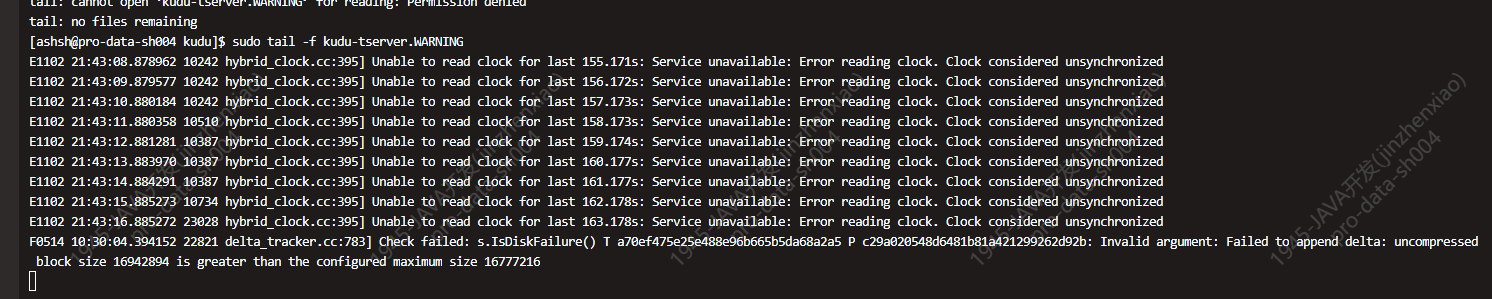
尝试删除下线该节点,看故障节点下线后服务是否会恢复。
事实及后续操作证明了这是不可行的,这样做的结果只是消除了这个异常,但是 Kudu 服务本身还是在继续出现问题。
第二个排查点
重启节点无果后,开始关注问题本身 RPC connect closed。
开始查找相关资料,熟悉了 Kudu 各服务模块所承担的角色及任务功能,详细信息参见 博客地址。

加上 Dolphin 任务调度后异常的日志,基本可以判断是 Kudu 的 tablet server 导致的异常。
| 服务角色 | http端口 | rpc端口 |
|---|---|---|
| master | 8051 | 7051 |
| tablet server | 8050 | 7050 |
第三个排查点
最终有了一些线索,开始排查 Kudu 的各服务状态。
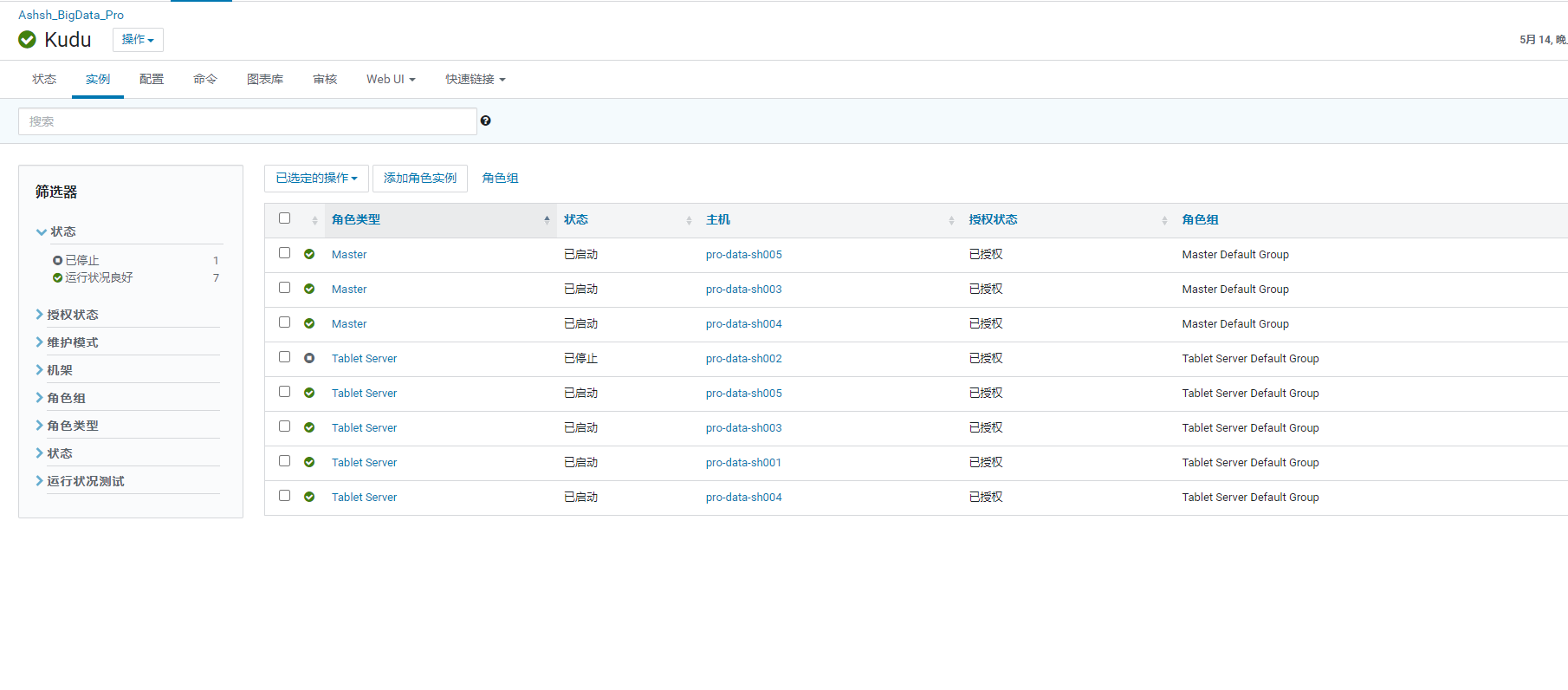
发现 Tablet 服务集群中的 3,4 节点都在出现问题。
原因应该是其上游服务 (Impala, SDC, …) 与 Kudu 通过 RPC 服务通信时,由于 03,04 节点宕机,导致上游服务也出现问题。
恢复
资料
好消息是异常点定位到了,但坏消息是如何解决这个问题。
通过互联网搜索,找到了两篇相关的博文:
操作
通过上述博客的指导,进行了一系列操作。
拉取报告
sudo -u kudu kudu cluster ksck pro-data-sh003,pro-data-sh004,pro-data-sh005 > ./ksck.out 2>&1
# 命令详解
# `sudo -u kudu` 使用kudu用户执行语句
# `kudu cluster ksck` 表示使用 ksck这个工具
# `pro-data-sh003,pro-data-sh004,pro-data-sh005` 为kudu 集群的主节点机器名
# `> ./ksck.out 2>&1` 表示将结果输出至 ./ksck.out 文件
通过这条命令拿到kudu的健康检查报告 ksck.out
构建修复脚本
import re
# 读取文件 ksct.out
start_flag = False
process_index = 0
command_list = []
command = 'sudo -u kudu kudu remote_replica unsafe_change_config ${replica_node} ${tablet_id} ${replica_id}'
with open('ksck.out') as ksc:
# 读取文件内容
ksc_contents = ksc.readlines()
for ksc_content in ksc_contents:
# 判断内容是否匹配正则 `(Tablet (.*) of table)`
if re.match(r'(Tablet (.*) of table)', ksc_content):
start_flag = True
# 只取读取文件内容的当前及后3行
if process_index > 4:
command = 'sudo -u kudu kudu remote_replica unsafe_change_config ${replica_node} ${tablet_id} ${replica_id}'
start_flag = False
process_index = 0
# 取内容
if start_flag:
process_index += 1
# 当前行, 取出 tablet_id
if process_index == 1:
tablet_id = re.match(r'(Tablet (.*) of table)', ksc_content).group(2)
command = command.replace('${tablet_id}', tablet_id)
if process_index > 1:
# 正则匹配 `(.*) (\(pro-data-sh00[0-9]:7050\)): RUNNING`
if re.match(r'(.*) (\(pro-data-sh00[0-9]:7050\)): RUNNING', ksc_content):
# 第一个捕获的为replica_id , 第二个捕获的为 replica_node
match_result = re.match(r'(.*) \((pro-data-sh00[0-9]:7050)\): RUNNING', ksc_content)
replica_id = match_result.group(1)
replica_node = match_result.group(2)
command = command.replace('${replica_id}', replica_id)
command = command.replace('${replica_node}', replica_node)
command_list.append(command)
print(command_list)
# 将command_list 写入到一个名为 fix_tablet.sh 的文件中
write_index = 0
file_index = 0
with open(file=f'./fix_tablet.sh-{file_index}.sh', mode='w', encoding='utf-8') as fix_tablet:
fix_tablet.write('#!/bin/bash\n')
fix_tablet.write('echo "执行开始"\n')
# 每一百条分割一个文件
for write_command in command_list:
if write_index != 0 and write_index % 100 == 0:
file_index += 1
fix_tablet.write('echo "执行结束"\n')
# 重新打开一个文件
fix_tablet = open(file=f'./fix_tablet.sh-{file_index}.sh', mode='w', encoding='utf-8')
fix_tablet.write('#!/bin/bash\n')
fix_tablet.write('echo "执行开始"\n')
fix_tablet.write(f'{write_command}\n')
# linux命令暂停1秒
fix_tablet.write(f'sleep 1\n')
fix_tablet.write(f'echo "执行第{write_index}条"\n')
write_index += 1
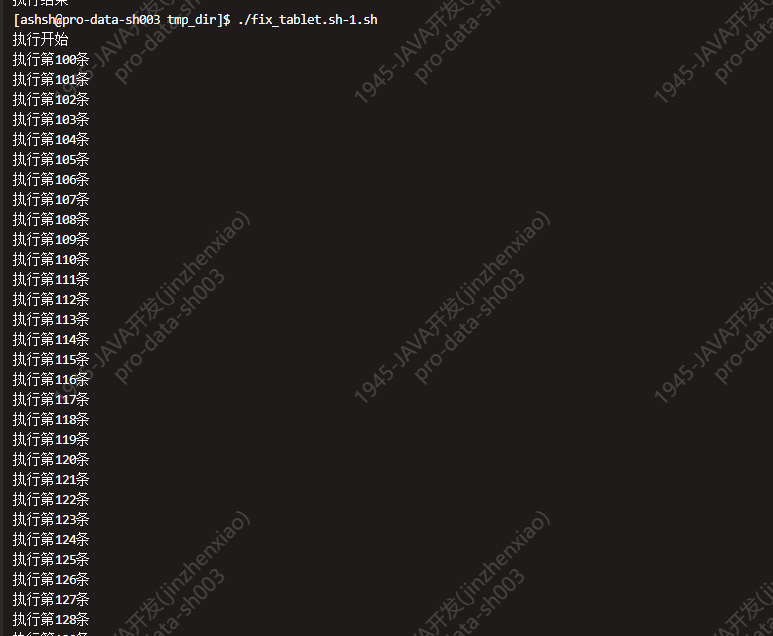
通过上面这个脚本将 ksck.out 中的错误报告拆分为修复脚本中的一条条命令, 脚本文件命名为 fix_tablet-*.sh (每百条分片为一个文件).
例如将 报错信息
# Tablet 4523ee9b9e5d4e67b74de1d3e6c0a7e0 of table 'impala::kudu_pro.wms_yb_iostorage_detail' is unavailable: 2 replica(s) not RUNNING
# c29a020548d6481b81a421299262d92b: TS unavailable
# fc47010673be46cfbe5cc58d2868b43d: TS unavailable
# 9ca534be0ca342409553acea7f5e7c1b (pro-data-sh005:7050): RUNNING [LEADER]
调整为语句
sudo -u kudu kudu remote_replica unsafe_change_config pro-data-sh005:7050 79e0907e251644a49cd57bb79024b4df 9ca534be0ca342409553acea7f5e7c1b
# 命令详解
# 该语句作用是对tablet的replicate节点做调整,只保留语句中所配置的replication node
# `sudo -u kudu` 使用kudu用户执行语句
# `kudu remote_replica unsafe_change_config` 使用客户端工具命令
# `pro-data-sh005:7050` 对应tablet的 `LEADER` 节点通信地址端口
# `9ca534be0ca342409553acea7f5e7c1b` 对应的replication UID
执行脚本
逐个执行脚本,直至所有脚本都执行完成后,可以看到的现象就是 pipeline 可以正常写入 Kudu, Dolphin任务也执行正常了。
其他
上述流程中留了两个坑 (可能还不止 doge), 因为跟主流程不搭嘎, 所以就安排在这补上.
错误日志
关注排查点1的错误日志中的一句话 Failed to append delta: uncompressed block size 16942894 is greater than the configured maximum size 16777216。
配置项
锁定到了对应配置的配置项
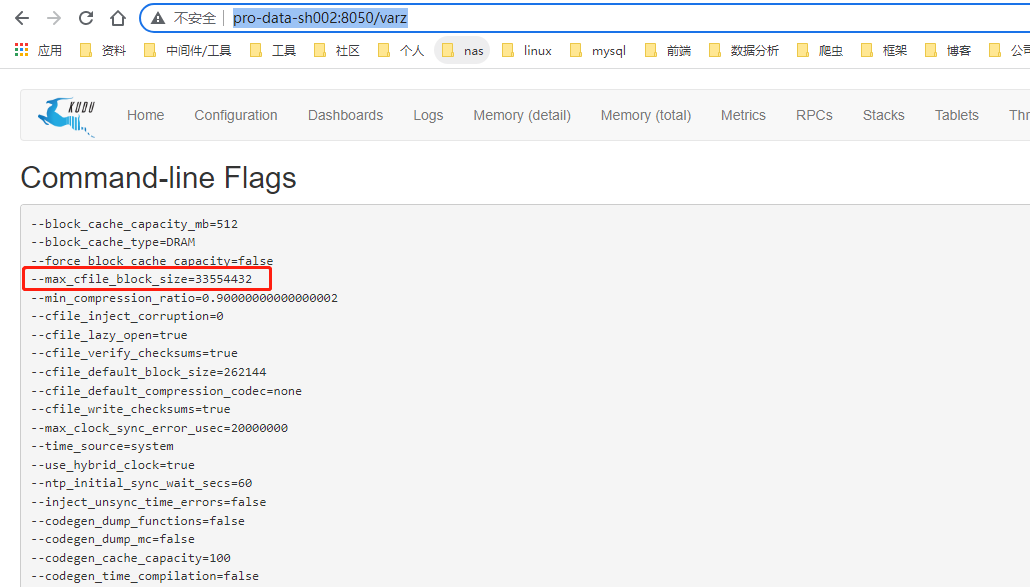
该页面可通过 teblet_node:port/varz 访问
配置调整 + 重启搞定
调整配置后, 重启该异常消失,同时tablet server 02节点重启也不再异常
下线的 Tablet 02 节点
之前排查过程中因为
02节点一直宕机,所以直接将02节点下掉了。
由于 kudu 表 tablet 对应 replication leader 节点都分布在 02,05节点。 在 02 节点下线后,在进行读操作时查询某些 replication leader节点在 02 机器上的表会查询超时,导致上游服务查询异常报错。
于是在将该节点重新上线后, 数据应用服务查询也了恢复正常 .
相关资料
相关博文
- https://segmentfault.com/a/1190000021635655
- https://blog.csdn.net/m0_37534613/article/details/96591677
- https://www.cnblogs.com/barneywill/p/10581678.html
- https://zhuanlan.zhihu.com/p/426901943
官方文档
- https://kudu.apache.org/releases/1.5.0/docs
其他
- https://github.com/apache/kudu
- https://issues.apache.org/jira/projects/KUDU/issues