初识SpringBoot-第八篇:SpringDataJpa整合
Java Persistence API是一种标准技术,可让您将对象“映射”到关系数据库。该
spring-boot-starter-data-jpaPOM提供了上手的快捷方式。它提供以下关键依赖项:
- Hibernate:最受欢迎的JPA实现之一。
- Spring Data JPA:使实现基于JPA的存储库变得容易。
- Spring ORMs:Spring Framework的核心ORM支持。
本文不会详细介绍JPA或Spring Data。您可以按照“访问数据与JPA” 从官网spring.io阅读SprignDataJPA和 Hibernate的参考文档。
Spring Data JPA详细介绍
常见的ORM框架中Hibernate的JPA最为完整,因此Spring Data JPA 是采用基于JPA规范的Hibernate框架基础下提供了Repository层的实现。Spring Data Repository极大地简化了实现各种持久层的数据库访问而写的样板代码量,同时CrudRepository提供了丰富的CRUD功能去管理实体类。
优点
- 丰富的API,简单操作无需编写额外的代码
- 丰富的SQL日志输出
缺点
- 学习成本较大,需要学习HQL
- 配置复杂,虽然
SpringBoot简化的大量的配置,关系映射多表查询配置依旧不容易 - 性能较差,对比
JdbcTemplate、Mybatis等ORM框架,它的性能无异于是最差的
ORM对比图
以下针对Spring JDBC、Spring Data Jpa、Mybatis三款框架做了个粗略的对比。一般应用的性能瓶颈并不是在于ORM,所以这三个框架技术选型应该考虑项目的场景、团队的技能掌握情况、开发周期(开发效率)…
| 框架对比 | Spring JDBC | Spring Data Jpa | Mybatis |
|---|---|---|---|
| 性能 | 性能最好 | 性能最差 | 居中 |
| 代码量 | 多 | 少 | 多 |
| 学习成本 | 低 | 高 | 居中 |
| 推荐指数 | ❤❤❤ | ❤❤❤❤❤ | ❤❤❤❤❤ |
前期准备
创建项目
老规矩.. 一如既往使用spring initialiizr创建
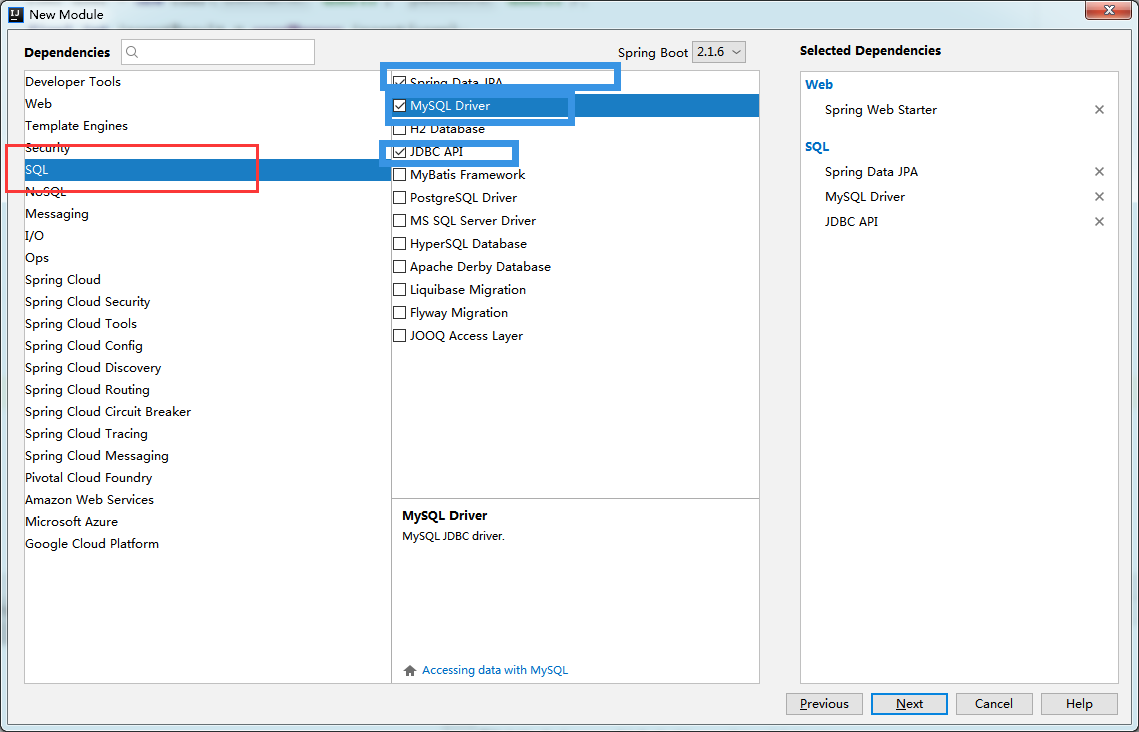
pom.xml
<!-- jpa整合包 底层使用Hibernate-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- mysql 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 测试包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
结构图
application.yml
具体配置项可查看 JpaProperties(prefix=”spring.jpa”)配置类
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/chapter7_jpa?serverTimezone=UTC
username: root
password: 1234
jpa:
hibernate:
# 项目启动时更新或者创建数据表结构
ddl-auto: update
# 项目运行过程中 控制台打印sql
show-sql: true
代码操作
配置bean
编写一个实体类(bean)和数据表进行映射,并且配置好映射关系;由于我们在全局配置文件中配置了
spring.jpa.hibernate.ddl-auto选项,所以我们可以直接先不用再数据库中建表,直接由待会项目启动时由项目自动创建,
ddl-auto 几种属性
- create: 每次运行程序时,都会重新创建表,故而数据会丢失
- create-drop: 每次运行程序时会先创建表结构,然后待程序结束时清空表
- upadte: 每次运行程序,没有表时会创建表,如果对象发生改变会更新表结构,原有数据不会清空,只会更新(推荐使用)
- validate: 运行程序会校验数据与数据库的字段类型是否相同,字段不同会报错
详细参考下方示例代码:
package com.shawn.chapter7springdatajpa.entity;
import javax.persistence.*;
//使用JPA注解配置映射关系
@Entity //告诉JPA这是一个实体类(和数据表映射的类)
@Table(name = "t_user") //@Table来指定和哪个数据表对应;如果省略默认表名就是user;
public class User {
@Id //这是一个主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键
private Integer id;
@Column(name = "user_name",length = 50) //这是和数据表对应的一个列
private String userName;
@Column //省略默认列名就是属性名
private String email;
public User() {
}
public User(String userName, String email) {
this.userName = userName;
this.email = email;
}
...省略getter setter
创建dao接口继承Repository
编写一个Dao接口来操作实体类对应的数据表(JpaRepository)
package com.shawn.chapter7springdatajpa.repository;
//继承JpaRepository来完成对数据库的操作 接口泛型<实体类对象,主键类型>
public interface UserDao extends JpaRepository<User,Integer> {
}
测试
测试建表
启动项目,通过配置项我们发现表已经建成功了
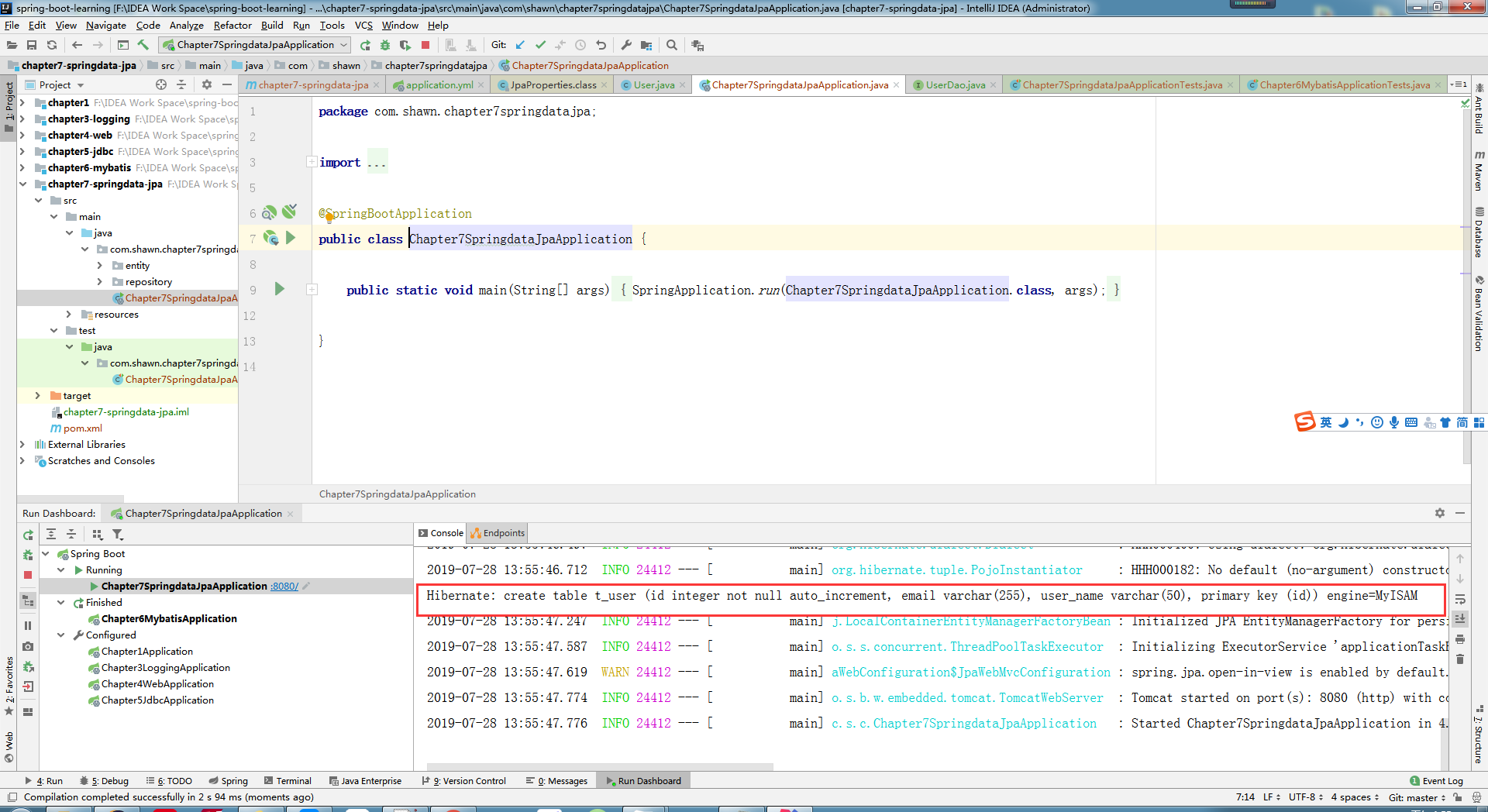
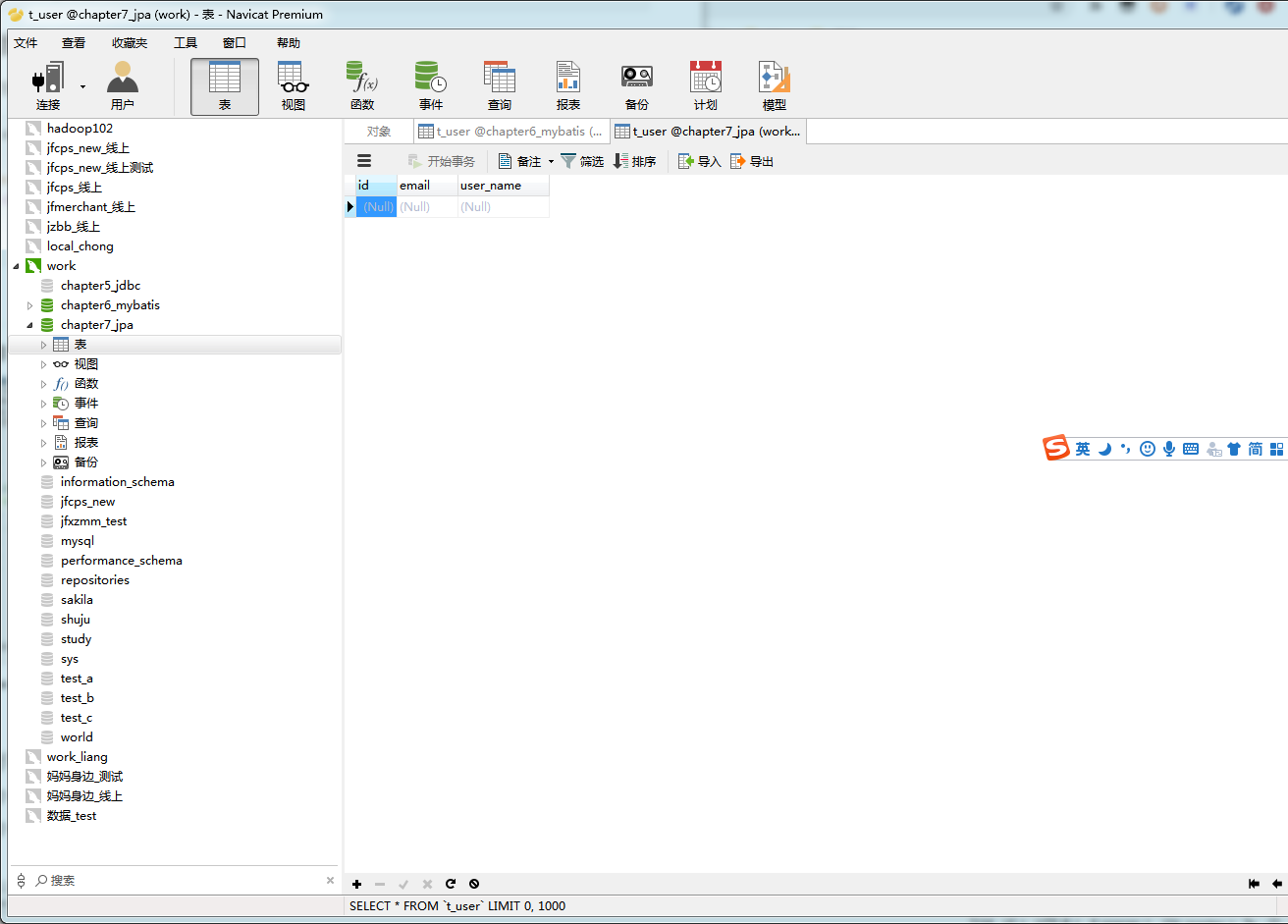
测试接口
接口就简单测个插入查询吧
package com.shawn.chapter7springdatajpa;
@RunWith(SpringRunner.class)
@SpringBootTest
public class Chapter7SpringdataJpaApplicationTests {
private static final Logger log = LoggerFactory.getLogger(Chapter7SpringdataJpaApplicationTests.class);
@Autowired
UserDao userDao;
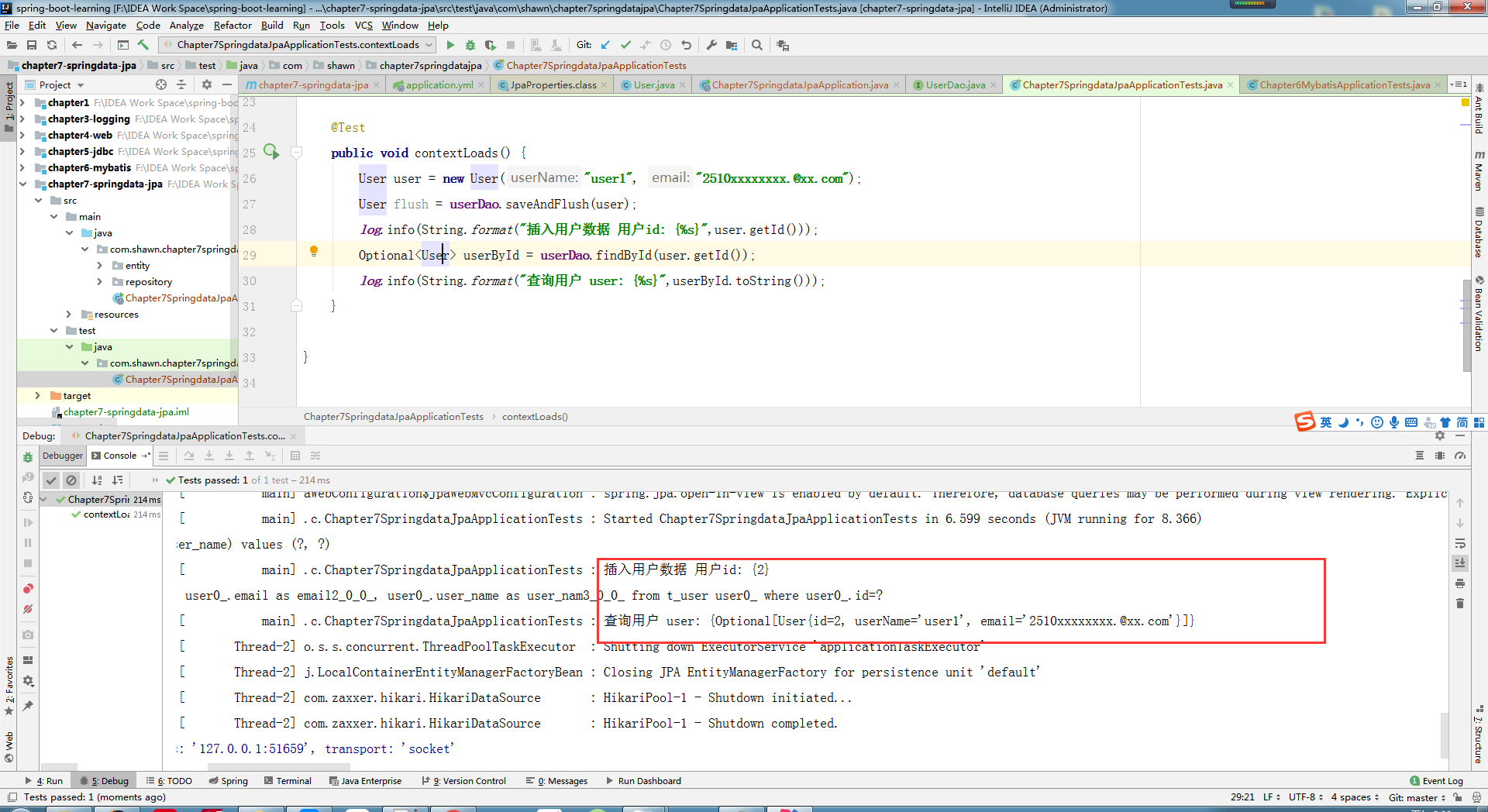
@Test
public void contextLoads() {
User user = new User("user1", "2510xxxxxxxx.@xx.com");
User flush = userDao.saveAndFlush(user);
log.info(String.format("插入用户数据 用户id: {\%s}",user.getId()));
Optional<User> userById = userDao.findById(user.getId());
log.info(String.format("查询用户 user: {\%s}",userById.toString()));
}
总结
以上就是springdatajpa整合过程,相关资料如下